We Don't Have To Put Up With Broken Search
Fixing Search
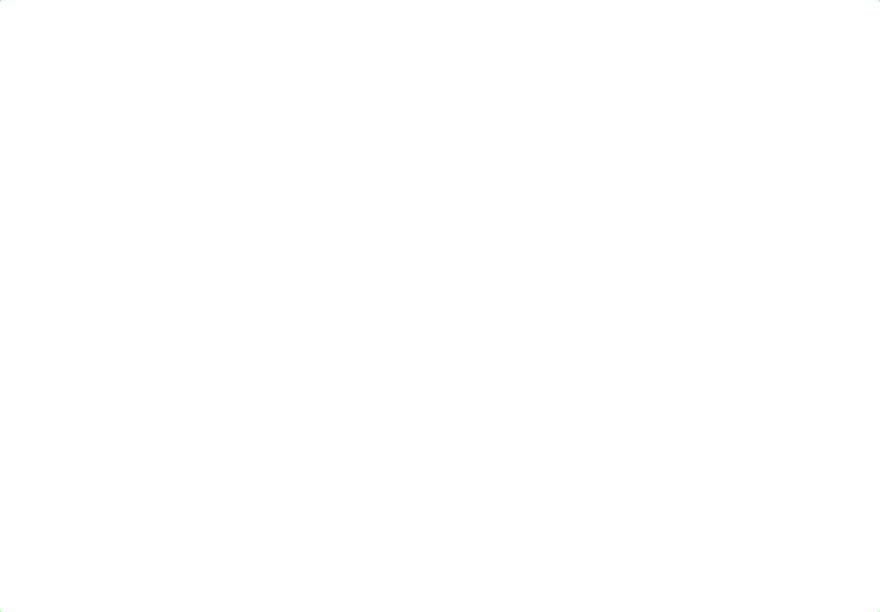
This week and next, all of tech policy is dizzily watching Google be put on trial by the US government for monopolisation of search. While it might be too early to call it "the antitrust case of the century" as some have (we've still got over seven decades and plenty of monopolies to eradicate), it's certainly a major case. Whether the accusations stick or not is up to the court but it's obvious either way that the web would be a better place without Google Search. Google's quality has been steadily dropping over the years, to the point that no one is even surprised when it gets caught making up a completely fake Shrek 5 movie (see image below), further ascribing it a 92% rating amongst Google users. (I'll concede that collecting data on made-up users instead of on real ones is an improvement, I guess it's in the "Privacy Sandbox" somewhere.) As Cait, who was looking for Shrek's further adventures, concludes, "you can't even tell people to google things anymore. You are just sending them into a den of lies."
We need to rethink search on the web for multiple reasons:
- If Google is found guilty, something about how search operates will have to change.
- If they aren't, effecting change will be harder but we still need a plan. The web can't work if most people aren't accessing a serviceable search engine.
- The web's implicit current architectural approach to search is broken. If we get rid of Google today but change nothing else, we'll just get another Google.
Changing search on the web is less daunting than it sounds (getting rid of entrenched incumbents aside). There is no law of technology stating that search has to work the way it does today. The architecture we have is a mix of historical accidents, laziness from technologists who are slow to spot problems, and deliberate decisions by a small handful of powerful companies. We can make different decisions, and the alternatives are feasible.
How does search work?
To give context on alternatives, it's worth making a very brief summary of how search works today and why the problems with this architecture compound into producing the ailing web that we can observe today. I look at three aspects: search and publishers, the search engine interface itself, and search and browsers. I deliberately don't look at AI as one of these aspects, no matter how fashionable it is. That's because it doesn't affect the structure of the situation, it only worsens the existing problems. We need to fix search irrespective of the gobbledygook machines.
The historical relationship between publishers and search engines was a simple and rather fortuitous mutualistic affair: publishers made their content freely available for search engines to index, which benefits the latter by making them relevant, and in turn the search engine would only use that content to index it and make it searchable by its users. That benefitted publishers by driving more traffic to them.
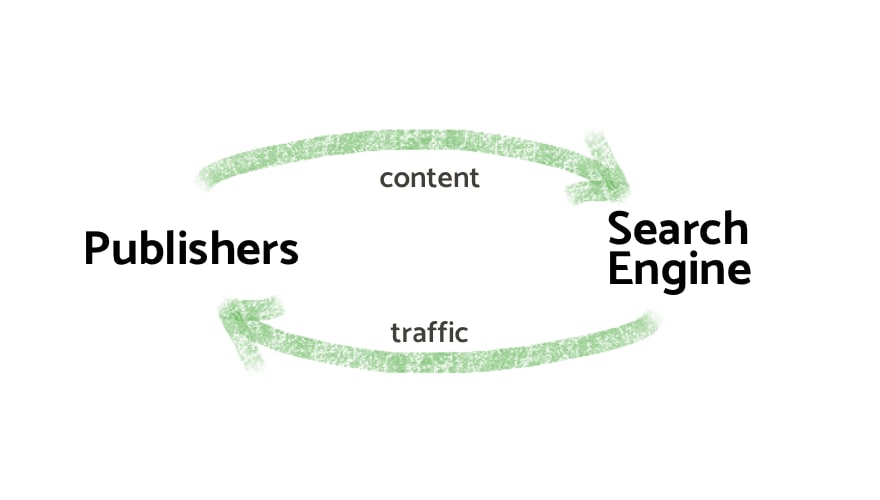
Some of the less savvy publishers complained, but overall this was a good arrangement. The fact that it emerged in the absence of a deliberate deal or of standardised interfaces between the two was quite impressive. Unfortunately, for this kind of mutualistic symbiosis to persist over time, there needs to be a quick feedback mechanism to punish a defecting party trying to get more out of the relationship than it puts in. For publishers, that mechanism is simple: if they don't provide content, they don't get traffic. The incentive to cooperate is strong. For search engines, the control mechanism is competition. So long as there's competition between search engines, if one of them starts being extractive with respect to publishers then publishers can simply exclude the engine using robots.txt. Sure, they'll lose a little traffic but the search engine suffers from less relevant results (especially as it's likely that many publishers would make the same decision), losing users.
That model held for a while, but as search became increasingly monopolised it started failing. When traffic from a single search engine is your livelihood, you no longer get a say in the relationship: you just do as you're told, no matter how much it hurts you. As Google came to dominate, it started simultaneously doing more with the content than just indexing it, demanding more of publishers, and sending less traffic. In the absence of corrective mechanisms, the relationship shifted from mutualistic to parasitic.
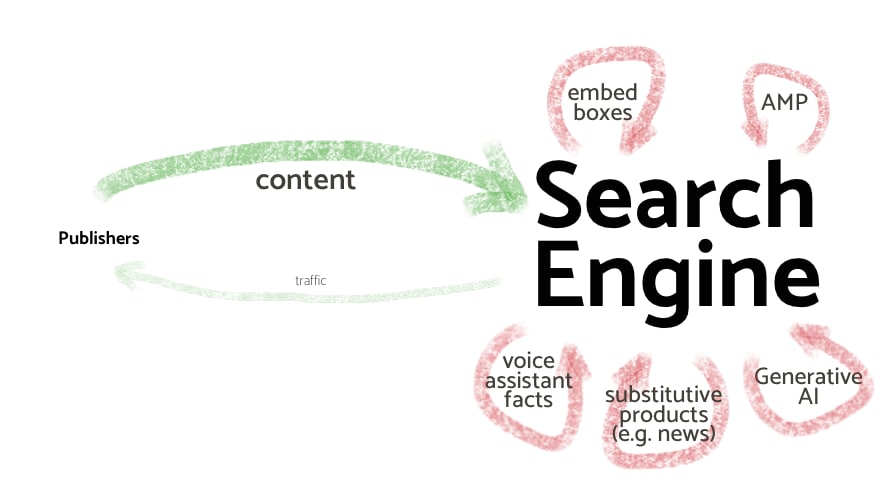
Unsurprisingly, when you take more out of a resource than you put back in, that resource suffers. The effect is not immediate (and therefore doesn't correct behaviour fast enough) but the resource will fail to regenerate, and over time it will become damaged and depleted. That is what I mean when I say that search has become extractive. It's death by a trillion hits: every time search terminates at the search engine (or sooner, as when a voice assistant replies with a fact extracted from a publisher) instead of going to the publisher's property that's a shaving of a penny less that goes into supporting publishing. Individually, that's imperceptible, but there's on the order of a trillion () searches every year: it adds up.
That's the first architectural problem: there is no mechanism ensuring that the publisher ⟺ search engine relationship remains mutualistic. At the very least we ought to restore competition, but should consider more intentional approaches to govern this cycle.
Second aspect, this is not obvious to many but at the end of the day a search engine, as presented to people, is just a web site. There's nothing special about a search site — I could index some content and make it searchable here on berjon-dot-com and that'd just work — and conversely a search site can do everything that any site can do. That has the advantage that it's straightforward and expedient: no need to invent any new standard or do any special work, and search engines can offer whatever experience they want. It has its downsides, however. First, website output is irregular and not easily reusable. This makes it challenging for instance to source a search from multiple engines and present it in a usefully merged manner. It also gives complete control over the experience and parameters to the search engine when it would be better if these were under the user's control. Overall, the flexibility and expediency of the current approach has mostly been used for "innovations" that are hostile to users (and publishers).
That's the second architectural problem: web search as supported today limits user agency and doesn't empower other parties to experiment with new interfaces, multi-sourcing, or new business models. We would be better off with standardised and reusable search infrastructure, it would liberate innovation.
And the third and final aspect is that browsers are paid to select the default search engine for you. Browsers pride themselves on being "user agents" which is to say that they work for you and are supposed to act only in your best interest. For search, you'd expect that to entail that they would evaluate a variety of engines for user experience, privacy, results quality, etc. and pick the best. Or even better, they could evaluate search engines and provide people with a guided wizard to pick the one that best matches their preferences. There are plenty of ways in which browsers could fulfil their fiduciary duties to users in getting people the best search experience possible. Instead, they sell your search traffic to the highest bidder.
Don't get me wrong, that we have a way to pay for browsers at all is good. Browsers (especially browser rendering engines, the beating heart of the beast) are enormously complex products that provide a public good and that require very significant investment. Maintaining the current level of quality and pace of evolution in browsers requires about $2 billion per year. That's actually not that much money when you consider the scale of the web and how central browsers are, but it still needs to come out from somewhere. We need to maintain access to that funding one way or another.
However, browsers selling users to search engines to keep the web going is a bit like selling weapons in a war zone to bankroll cancer research. As mentioned, it's a betrayal of users, which is already a concern, but it also has effects that are very detrimental to the web as a whole.
It's important to understand that very, very few people ever change their search default. Many don't know they can, or how, or why. To most users — and this is a point that technologists rarely appreciate — the browser and the search engine are one and the same thing. Telling people that they can swap the search inside their browser is like (if you know as much about cars as I do) when your mechanic friend is excited to recount how they replace that thing under the hood with, uh, another thing also under the hood and the car somehow cars better afterwards. You nod, you make some interested sound involving eyebrows, you smile, and you get them another beer. That's why it's worth buying the default: you're basically buying the user.
The effect of search defaults is to create a feedback loop in which the engine that can afford to pay the most wins the bid to be the default, which makes it richer, which enables it to pay the most. Search defaults are the moat for search engines, they're basically all of the moat. And the end result of this runaway feedback loop is that it guarantees that there will be almost only one search engine. It's a bad market structure. It also almost guarantees that that search engine won't be the best that can be made, it will only be the one that happened to put the most money down when the process started.
Search defaults therefore contribute to breaking the publisher ⟺ search engine relationship by breaking competition. By limiting search diversity, they encourage a world in which only one hegemonic ranking matters, which diminishes the quality and resilience of the epistemic ecosystem across society. Search ranking is an editorial decision; having a single editorial decision-maker ranking the relevance of all information is incompatible with democracy.
Worse, a search monoculture is much easier to optimise for when compared to a competitive search market with different methodologies. This means that people will eventually become good at gaming it (because there is a high incentive to do so). In turn, 1) search result quality will invariably drop as it becomes dominated by content optimised for ranking rather than for people and 2) the web itself will fill up with SEO-optimised garbage, which harms the quality of web content available to all, even those who don't use the dominant search engine. Have you ever wondered why every cooking recipe on the web has a twenty page biopic preamble? Because Google likes it better that way.
And the problems don't stop there. Having a single search default also means that there is only one search engine for all topics, when result quality and user experience would be better served by search verticals specialising in a given topic. A different browser interface could lend itself well to that, but the current approach locks us into a one-size-fits-all general-purpose search engine that is mediocre at everything.
How much money gets paid to browsers to be the default search engine is a direct measure of how little the product's quality is able to attract users. Every product has user acquisition and retention costs, but when you're market leader by enough of a margin that there's no real second and your brand is universally recognised to the point of being a verb for the activity, those costs really shouldn't be that high. But they're in the tens of billions — because search defaults are how you buy the search market. The business model of browsers — and their architectural purpose in web search — is to serve as muscle-for-rent to enforce search dominance.
Clearly, buying the default search placement from browsers (and operating systems) is a problem with serious negative consequences. We need to look for a way to keep browsers funded that is less harmful to society.
How do we fix this?
Effecting change at this scale isn't trivial even if the technical solutions are relatively simple, and getting there will require either very strong consensus in the web community (which is possible but unlikely given both the influence of incumbents and how much money is in play for browser vendors) or determined policy intervention. Such fixes could be mandated behavioural remedies, developed in partnership with the relevant standards organisation.
The first part of the fix is that search engines should not be exposed to people as web sites. Instead, they should be an API that the browser accesses and renders itself. (For non-technical people, this means that your browser would get data describing search results from one or more search engines, and show it to you in the way you prefer.)
API-based search isn't new (in fact it used to be the expected approach) and it comes with multiple benefits:
- Algorithmic choice: the browser can retrieve a bag of results and reorder them for you, according to your preferred ranking method.
- Multi-sourcing: the browser can retrieve results from multiple engines and merge them together seamlessly.
- No UI shenanigans: you would no longer have to contend with dirty tricks from the search engine filling half your screen with ads, trying to make ads look like results, getting you to log in, or trying to keep you on the search engine.
- No abuse of power: decoupling the indexing work done by the search engine from the user interface means that abuses of power in which the search engine forces publishers to support new formats (e.g. AMP) become much harder to support.
- Privacy: today's search engines are able to collect a lot of data about people. They know not just what you search for but also which link you click on, and may be tracking you elsewhere on the web or via the browser. (Not all choose to do this, but all can.) The browser can be (and, aside from Chrome, would certainly be) far more protective. To the extent that search engines benefit from a statistical understanding of which results are preferred by people, this information can be provided to them in aggregate and anonymised.
- Extensions: browsers support extensions and these could be used as a great way to experiment with new search result interfaces as they are able to modify the user interface.
- Easier vertical search: once your browser is no longer sold to a specific general-purpose engine, it can provide much better user interface to make it easy to use search verticals. This ought to significantly improve people's experience.
Of course, APIs are nice but someone needs to be pay the search engines given that under this approach they can no longer show ads. Given the browser's control over the UI, there are multiple options and different users can make different choices. One option is that the browser would itself show ads as part of its displaying the results. Before you scream, consider that if the browser selects the ads, it can be done in a very privacy-centric manner, doubly-so because search ads are highly contextual/intentional (you can pick ads based primarily on the search terms). Browsers could partner with privacy-centric adtech companies (e.g. Kobler) for such purposes. Alternatively, people could simply top up some money that their browser has access to and pay for their search, getting a totally ad-free experience. No matter how the money comes in, what's important is that people must not need to create an account with search engines and pay them directly. Instead, browsers would pay per API call, using for instance ILP. It's a few moving parts but none of this is rocket surgery.
API search is a necessary brick for a sustainable and high-quality web search architecture, but it is not sufficient. It needs to be coupled with a strict no default search policy. No browser is allowed to pick default search sources, and certainly not to be paid for it. The web standards process can establish eligibility, labelling, and filtering criteria that align with web values so that browsers can offer their users informed choices and a great experience guiding people to the best search options for them, while keeping junk options at bay. (Experience with choice dialogs has shown that quite a few garbage search engines will try to game the system. Constraints on privacy and the API can do a lot to prevent those from emerging in the first place.) As part of this process, it would help if browsers were put under strong, legally enforceable fiduciary duties with respect to the users they represent online. (I will return to this in a future post.)
I believe that these two constraints, APIs and no defaults, are sufficient to fix search, or at least to address the problems that the current web search architecture creates. This approach is technically realistic. Note that since, in this proposal, funding flows from browsers to search engines in an explicit way, a fraction of it can be earmarked to finance browsers and browser rendering engines. This does not create more taxation than already exists (since it draws funds from the same source: search) but does not require that browsers sell out their users.
I will not dive into the more complex topic of what publisher rights should be and what purposes search engines should be allowed to freely index for. Indexing purposes that don't create a regenerative loop such that publishers benefit from traffic (or something else) in exchange are problematic because they eventually lead to the exhaustion of supply (or at least of quality supply). It's an issue that needs addressing, but it can be solved separately.
We'll know soon enough if Google will be found guilty or not and what the result of that decision will be. But irrespective of that case's outcome, there is no reason for policymakers and the custodians of the web alike to keep sleepwalking through a broken architecture that everyone is suffering from. Better options exist and are feasible — if we don't just default to what others have picked.
Acknowledgements
Many thanks to Daniel Davis for constructive feedback (and spotting typos). Thanks also to Jeffrey Yasskin for pointing out technical issues with some links.