It’s not futile
Capture Resistance

For the longest time, word was that the Web would free the world; now, it seems as if most of the world wants to liberate the Web.
There is much talk of antitrust, competition, and contestable markets, and I have no doubt that we need lawyers, economists, and regulation to chart a path to a better Web. But tech can and should play its part too and indeed talk of decentralisation is (fittingly) everywhere and all over the place, in the bizarre ménagerie of web3 that ranges from ape cryptobros to co-op socialists but also well beyond that community. A broader rekindling of interest in decentralised computing is burgeoning.
It is unclear, however, that just wanting decentralisation is enough to make it happen. As Stephen Diehl put it, “There's already a decentralized internet. It's called the internet.” If we’re not too happy with how decentralisation has played out so far, we might benefit from taking the time to understand why.
A decentralised system, in the sense of not having a topologically central point of control, is neither necessary nor sufficient to eliminate the excessive concentration of power that a party may hold over others in the system. Hypertext is decentralised but the Web can still be captured by controlling discovery or browsing. Token-based governance may share power but is susceptible to plutocracy. Conversely, a centralised system operating under institutional rules of democratic access can (imperfectly) resist the excessive accrual of power — see for instance Wikipedia.
A recent and excellent IETF draft from Mark Nottingham defines centralisation as “the ability of a single entity (e.g., a person, company, or government) — or a small group of them — to exclusively observe, capture, control, or extract rent from the operation or use of a Internet function.” It goes on to provide a useful typology of centralisation, discusses why some naive solutions don’t work, and offers high-level considerations for Internet (and Web) standards that ring very true to me. I recommend reading it. What I want to suggest is that we take Mark’s framing and distill it further into tactical recommendations and best practices that can be used to assess all new tech as well as mitigate vulnerabilities in existing ones. (Update: Protocol and Engineering Effects of Consolidation from Lazanski & McFadden is also worth reading and points in the direction of switching the community approach to centralisation from descriptive to prescriptive so that we may defend against it.)
The fields most commonly associated with decentralisation are distributed computing or networking, but in practice the closest branch is arguably cybersecurity. Centralisation results in another entity being able to overpower your ability to operate your system according to your intentions. It develops over time through various types of capture that include, as listed in the IETF draft, observing your operations (breaching confidentiality, appropriating trade secrets such as the behaviour of people on your property), controlling your system (forcing you into choices that are inferior from business and technical perspectives), or extracting rent which, by any meaningful measure of its impact, is often indistinguishable from extracting ransom.
This isn’t to say that the concrete tools of cybersecurity can be applied directly to decentralisation, but rather that security methodologies can inform the development of capture resistance as a pragmatic practice. Even though security is never perfect and there is real disagreement over approaches, it lends itself to consensus as to who is a bad actor and which practices can effectively mitigate risk. As a field, security has experience bridging technical measures to law enforcement and economic incentives that is directly applicable to decentralisation.
As indicated above, capture happens when an attacker is able to observe or control your operations, or to extract rent from them, and the accumulation of capture adds up to centralisation. Because capture is an iterated process, bad actors might not be able to deploy it with total effectiveness and in many cases the resulting centralisation is partial. More generally, capture does not have to be the result of a mechanical, compulsory process. A common component of capture attacks is to statistically rig the game so as to generate capture effects involving large populations even though, technically, any one of those people could have resisted the statistical nudging. A good example of this is using defaults to move laterally and project power from one space into another rather than compete on the merits. (Defaulting the search engine, browser, or mapping provider are all typical examples of lateral capture.)
Capture is, as is hinted at by the connotation of violence that it carries, an attack: when capture succeeds (even partially), the operational performance of the technological system being captured is degraded because its owners lose control over it, lose revenue from it, and fewer people have access to better products or better technology. An architecture that is susceptible to capture has a vulnerability; and we can explore capture resistance through threat modelling and develop best practices for mitigation.
I don’t claim to be writing the book on capture resistance in this post, I am only outlining how we can think about it and the useful work that this concept can do for us to make decentralisation considerations more tactical. The goal is to develop the ability to review technical architectures for capture resistance, in line with existing practices such as Security & Privacy Self-Review, RFC6973, the I18N Checklist, or the A11Y Questionnaire. I also hope that exploring this topic can open a channel for cooperation with regulators. Some avenues of exploration follow.
First, information is power and a company developing the capability to observe the behaviour of users on another business’s products is a capture vector. More generally, extracting data across contexts is a major contributor to anticompetitive advantage. Privacy is first and foremost about people, but it also needs to protect businesses against the misappropriation of trade secrets. We need to grow our common understanding of privacy beyond a narrow understanding of personal data and extend it to the governance of data flows that impact people, including of actions that take place at a remove from personal data, for instance after anonymisation or through on-device methods. Preventing data from leaking, strictly forbidding user agents such as OSs and browsers from collecting data beyond basic telemetry and crashes, and enforcing purpose limitations whenever data has to be shared are all important mitigations. This is an area in which I believe that the community has enough experience to get into detailed threat modelling and mitigation practices.
We must prevent bad actors from using defaults to project power laterally between markets. The Web community should develop standard choice dialogs for browsers and search, including nutrition labels to help guide people make informed decisions over aspects of the options they cannot readily assess for themselves (eg. for privacy). For historical reasons this will also require better financing models for browsers, a hard conversation that is long overdue and must happen if we want a diverse and pluralistic Web instead of one captured by a self-reinforcing browser/search dynamic.
More generally, we need to address intermediation issues whenever they appear. Intermediation capture happens when an entity has power over relations between other entities. The Web came with promises of disintermediation, offering to remove the gatekeepers and bring power to the people. But many misunderstand gatekeeping as the power to publish when it fact it is the power to amplify to an audience and to determine what is relevant. A massive and persistent capture dynamic has centralised gatekeeping power in the hands of two companies and change (one push, one pull). Repairing the damage this has caused will require developing a sounder understanding of gatekeeping power, ridding the tech community of the dangerous delusion that neutral relevance exists, and developing sustainable interoperability in social, search, and aggregation.
We also need to do work to prevent opaque mechanisms from being used in place of open markets. Much has been said about the US State Attorneys General’s complaint that alleges that Google ran third-price auctions which they claimed were second-price and pooled the difference to inflate other bids to help make its offering look better than competitors’ and reap the benefits from winning more bids. Whether these allegations are true is for the courts to decide, but the fundamental problem is that the allegations should not be possible. It should be obvious to all involved in a market and easily proven, especially in a market that is a key infrastructrural component of the Internet, how auctions are operating and who wins what under which terms. Replacing a market with opaque mechanism design has two consequences. First, it captures the market since the mechanism will be optimised to benefit its designer rather than as a public good. Second, it captures the participants in the transactions because, in the absence of the information that a market normally provides, they lose the ability to take rational initiative and have to put their trust in charlatans — a situation that will sound familiar to those who know digital advertising. Preventing this kind of capture may prove harder, but can be worked on at the protocol level (and of course with regulatory requirements).
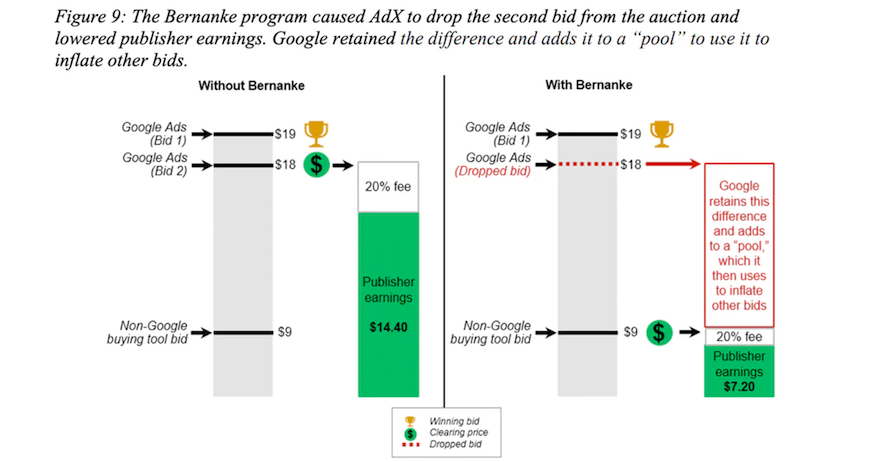
The more general issue of which replacing markets with designed mechanisms is an instance is that of infrastructure neutrality. When infrastructure ceases to be neutral, which is to say when the infrastructure system uses data about its users in order to manage their behaviour (an approach often labelled “smart”), it becomes decreasingly possible for them to act freely, rationally, and to take risks or innovate. Without infrastructures neutrality, the companies that operate on it lose the ability to learn about their environment, to adapt to it, or to develop a vision for their future because they are being too shaped by the infrastructure. This type of attack is often supported by not-owned-but-operated (NOBO) schemes that promise convenience but deliver control. Defending against NOBO capture using purely technical means can be challenging, but the Internet standards toolbox isn’t limited to technical means: we can also design institutions and governance systems. A key requirement here is that any infrastructural layer must be subject to either exit or voice (or both), which is to that either it must be easy and practical for participants to leave one infrastructure provider for another (thanks to portability and interoperability arrangements) or they must be a stakeholder with genuine influence (at the very least a modicum of control such as voting in their constituency) over the governance of the system. This applies to app stores just as much as it does to advertising infrastructure.
We used to treat security and privacy as annoying footnotes, internationalisation and accessibility as problems rather than opportunities. In none of these horizontal spaces is anyone perfect — but many are improving. Capture resistance is the next space to tackle, and developing the systematic ability to resist capture and to keep bad actors in check is key to building a robust, resilient Internet.
The danger of intermediation in particular cannot be stressed enough. Given the fast-growing complexity of our digital lives, we are facing with high probability and inside of a few years the dystopia of a single company inserting itself as the broker for all of our transactions with third parties. As a community, we need to become systematic and unforgiving in hardening our architectures against capture and we need to do it proactively rather than reactively. This requires an in-depth understanding of attack vectors and their mitigation.
In 2014, the IETF and the W3C agreed that “pervasive monitoring represents an attack on the Internet” and organised the STRINT Workshop to strengthen the Internet against pervasive monitoring**.** But state actors aren’t the only adversaries nor is pervasive monitoring the only attack. We find ourselves today at a juncture at which it is painfully clear that the Internet needs further strengthening along other dimensions — and I think it might be time for a STRINT-level effort in capture resistance.
Banner image from this wonderful collection. For their help in thinking about this topic I would like to thank, in no particular order: Mark Nottingham, Alex Cone, Ido Sivan-Sevilla, Keith Crawford, Sam Grubb, and John Prokap.