Towards a local-first, trustworthy Web
Web Tiles

User agents act as intermediaries between a service and the end user; rather than downloading an executable program from a service that has arbitrary access into the users' system, the user agent only allows limited access to display content and run code in a sandboxed environment. End users are diverse and the ability of a few user agents to represent individual interests properly is imperfect, but this arrangement is an improvement over the alternative — the need to trust a website completely with all information on your system to browse it.
RFC 8890: The Internet is for End Users, Mark Nottingham
What if that, but more?
Trust has been the defining constraint on the Web's evolution towards more powerful, more applicative capabilities. In a Web context, the user must be able to safely load any arbitrary URL, to safely click on any arbitrary link. The way in which this is achieved is that the runtime places strict limits on what a Web page can do, which in turn necessarily limits powerful capabilities.
App stores shift the trust around: apps get more powerful capabilities but there is a review and enforcement bottleneck at the store level which is load bearing for trust. This can open up more powerful capabilities but at the cost of producing a chokepoint for control, rent extraction, and self-serving policies. (You don't need me to fill out the details here.)
Meaningful digital systems cannot work without trust (users would face excessive direct harm and abandon ship) and that trust must be anchored somewhere. Thinking about this issue from an architectural standpoint, we need to keep in mind that we liberate more of the Web's power when we increase trust than when we add new features.
Offloading trust to the user is not a promising option either. Fifteen years of W3C workshops on permissions and consent on the Web (and many other similar efforts) have succeeded in only one thing: establishing that permissions and consent are not a promising avenue through which to extend the Web. More generally, installation ceremonies do not provide the means for people to reason about different security models and, in some cases, introduce undesirable differences between a page/app running locally or online.
Permissions are not just bad for security, they're also a bad user interface because they reduce a person's sense of agency. (Many thanks to Margaux Vitre for pointing me in that direction.) Asking people to approve access that they know they don't fully understand and that they couldn't monitor even if they did understand it does not empower them. On the contrary, it trains them to be despondent, helpless at the hands of the High Priesthood of Computer Whisperers. And our job as technologists building a better world is to eradicate the High Priesthood.
To make matters worse, the Web's trust model is anchored in the same-origin security policy. While this provides a relatively natural boundary for user agents to reason about, it makes it difficult to compose Web services safely, which is to say to have two or more Web pages cooperate to work for the user. Pages are not composable because novel threats emerge when two origins are allowed to communicate with one another. This puts stringent limits on the Web's ability to allow people to combine two services together, which in turn limits the Web's usefulness and prevents it from evolving an application architecture that is better than native apps. Such a novel architecture is there, in embryonic form, but, unless we tinker with the UI and architecture, the applicative Web will remain stuck in futile attempts to catch up to native apps instead of leapfrogging them. (Gordon Brander also makes a compelling case that an origin-bound Web naturally leads to centralisation.)
Capping this off, RFC8890 explains — quite correctly — that you don't want online services to be able to run arbitrary code with arbitrary access to your system. That makes intuitive sense, but there's a loophole: it implicitly assumes that what you care about, and most notably your data, is on your system. What happens if essentially all the data that matters most to you is not on your system but on someone else's? In that case — which is the common case today — the current browser-based user agent paradigm will not protect you from arbitrary access. Most of the time you'll have no option other than to trust some company that, more often than not, you know isn't trustworthy.
A Primitive Approach
A powerful way to improve the Web platform is to provide new primitives. A primitive is a capability that, on its own, likely doesn't do much that interesting. But a good primitive will be designed to interact usefully with existing (and future) parts of the stack, and this will enable it to enrich the platform across the board.
As a placeholder name, I am calling this new primitive a Web Tile. A tile is a set of content-addressed Web resources that, once loaded, cannot communicate further with the network. The goals and requirements of tiles are as follows:
- Tiles make it possible to grant a Web context access to more powerful capabilities — and notably to a person's private data — because they can be trusted not to exfiltrate data (at least not without deliberate user interaction and perhaps in ways that are subject to formal verification).
- One of the key relationships that Bernhard Seefeld proposes to invert in Inverting three key relationships in computing (which you should read) is that "Services come to the data (instead of data going to services)." This is powerful and can be made safe. One way to implement such a model is with sandboxed code (e.g. WASM that is constrained to certain operations, with some wonderful magic like IPVM) and that should be part of the toolbox, but many services also require — and in fact might primarily be — a UI. And if you have a perfectly sandboxed piece of WASM but have to interact with it through a UI that can make arbitrary network calls, you haven't solved anything much.
- Tiles are local-first and location agnostic. Because a tile cannot exfiltrate content, its content, once loaded, has to be sufficient to operate without touching the network. This means that no matter how the primitive is implemented, a tile can just be shuttled around without any impact on its functionality.
- Tiles are content-addressed, for multiple reasons. One is that this gives the tile a meaningful, stable origin (and every Web thing needs an origin, even though this one is different) that persists over time and across contexts without being bound to any location or DNS. Another is that saving or "installing" a tile simply means ensuring that it remains cached locally. Publishing a tile can happen offline. Content addressing can also help with more privacy-preserving retrieval since content can be loaded via indirections while guaranteeing its integrity. (For a discussion of the value of content addressing, see the IPFS Principles which I released earlier this year.) With content addressing, different implementations can make different trade-offs in terms of loading (e.g. more privacy for less speed) without this impacting anything else. One intriguing possibility would be loading CIDs over Veilid.
- Tiles are multi-device from the get-go. You can move a tile from your laptop to your mobile phone to your TV safely and effortlessly. If your user agent is a perimeter of devices, it can readily sync and maintain context across device boundaries.
- Tiles are designed to be composable. Having two or more tiles communicating together should not produce a threat profile different from that of any of those tiles in isolation (or that threat model can be reasoned about). By composing on the user agent, tiles can build a user-orchestrated application web (in lieu of monolithic web apps).
- By removing servers from the equation and moving the intelligence to the agent, tiles shift power to the user.
Anyone who has built anything on the Web should worry about the client-side nature of tiles however: servers are useful for quite a few things, or at least that's the common practice. I'm less worried about that than you might think, however. Given that tiles are a primitive that can already make itself useful, it can also be gradually complemented with a number of key APIs and with a specific client-side composition mechanism that makes it easy for tiles to work with one another to create sophisticated, user-centric experiences. This can be achieved with relatively minimal changes to how web pages are built and in a way that supports better user experiences.
What are tiles good for? Some very high level pointers:
- The UI primitive for the local-first Web.
- The interface of trustworthy services that come to your data rather than the other way around. (For older folks: like apps used to be.)
- Web content that can be more easily organised locally because its fully dependency tree can be understood by the browser.
- One of the Web's biggest failures has been its inability to kill PDF, despite how unresponsive and flat-out bad UX PDFs have. This could take it over the finish line, and they're even smaller because dependencies like fonts can be safely cached just the once.
- A good way to resolve the tension in RSS feeds between the limits of embedded data just linking to an online thing.
- A way to have arbitrary content on social media. Social media posts are heavily constrained because there's plenty that wouldn't be safe to embed — but (assuming sufficiently private loading, which this can offer) tiles as social content can address that.
- Apps that are built on composed tasks rather than siloed monoliths.
- A bunch more — adding trust can unlock a lot of power.
The biggest challenge is in browser UI: the tab centric model is a poor fit for applications and an even worse fit for composability. But because browsers make money by driving traffic to search engines, they have little incentive to support interfaces that don't centre on getting you to a SERP ASAP. (In fairness, this is not an insignificant change.) I do believe that we can bridge our way over (as some already have) and will get into greater detail in the PDS entry.
The main reason that I'm not going into great technical detail (I do exemplify the ideas more concretely below, but the details are all open to change) isn't because tiles are vapourware but rather because there are multiple implementation of the idea, with growing interest. Next-generation approaches to compute will need a user-facing component — and there are converging ideas about how to approach that, which I am unifying here under the broad label of "tiles". In April 2023, at IPFS Thing, Fabrice Desré from Capyloon (video), Ian Preston from Peergos (video), and yours truly from Protocol Labs (video, mentioning it in passing, referring to quick-and-dirty skunkworks prototyping on the idea) all presented the same idea. We concluded the conference with a workshop to iterate on the idea that also involved the folks from Fission who are working on IPVM (video).
The rest of this post goes into some detail about ways in which tiles and tile composition could work. If you are interested in thinking about how they could work and open to reading me being wrong a lot, proceed. If you just wanted to get a sense for the high-level idea, you can simply stop here!
What's A Tile
A tile is a DAG-CBOR of metadata and content, available over content-addressed protocols (likely IPFS since that's a family of protocols that includes anything that can retrieve a CID). This makes it somewhat similar to Web Bundles (which also use CBOR) but what differentiates DAG-CBOR from CBOR is that fields with tag 42 are registered as being CIDs (essentially, content-addressing links). This means that the tile isn't a package that contains all of the content needed for the tile but more like a manifest designed in such a way that the content can be loaded, discovered, cached, stored, etc. easily and independently.
The metadata is similar to that found in Web Application Manifests and the content is all of the Web resources needed to run this tile. I don't believe tiles should use the exact appmanifest format because tiles aren't a direct port of the notion of native app to the web, and there is mismatch — but reuse applies where possible.
The purpose of the metadata is to provide functionality equivalent to embedding cards (title, description, image, etc.) because tiles are expected not only to be rendered and run in full, but also to be listed for instance in search results or social feeds. This provides a hook into pages-as-objects that the web has struggled to hack together consistently and that is particularly useful in a content-addressed world. It is also a place to sign and assert authorship (and possibly other similar properties like peer review), to declare usage rights or child-appropriate flags, to capture declarative wishes, icons, and more.
Tiles load over the tile:// scheme and the authority is a CID, e.g. tile://bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi/. The CID is that of the tile's metadata document which, converted to JSON, looks like:
{
"name": "Fx Magic",
"description": "Fx Magic is a great image editor with plenty of great effects!",
"icons": [
{
"src": "fx.svg"
}
],
"resources": {
"/": {
"src": "bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi",
"mediaType": "text/html"
},
"/fx.svg": {
"src": "bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi",
"mediaType": "image/svg"
},
"/pretty.css": {
"src": "bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi",
"mediaType": "text/css"
},
"/app.js": {
"src": "bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi",
"mediaType": "application/javascript"
}
},
"wishes": [
{
"name": "Fx magic it!",
"can": "edit",
"what": ["image/*"]
}
]
}
Both name and description should be self-explanatory. They are used in contexts in which the tile is listed but not rendered, for instance in feeds, search results, social media timelines that can all list tiles. All icons must be listed in resources if they are to be resolved and used. The resources entry maps URL path components (in full) to CIDs and media types required to load and render them. These essentially mint URLs under the tile's authority, e.g. tile://bafy…/pretty.css and are resolved as such at runtime. The / resource is shown by default.
The wishes entry lists wishes that this tile can grant (see next section); in this case it is able to edit images.
The loading context imposes a CSP that might be equivalent to:
Content-Security-Policy: default-src 'self'
style-src 'self' 'unsafe-inline'
script-src 'self' 'unsafe-inline' 'wasm-unsafe-eval';
img-src 'self' blob: data:;
media-src 'self' blob: data:;
(Note: the exact CSP is subject to discussion, don't use the above as anything other than one example amongst many to give some some quick flavour.)
Composing Tiles: Wishes/Intents/Activities
Users want to accomplish tasks more than they want to use any given app. The app-centric model is limiting and the Web can do better. Web apps have so far been modelled on native apps: a blueprint for silos. Instead, we focus on dynamically linking tasks together to create a seamless flow of interactions.
The existing technology matching this approach is Web Intents. Web Intents were developed (and abandoned) by the W3C's Device APIs Working Group as a way to enable precisely the kind of composition described here between Web pages. They were inspired by Android Intents. A number of alternative designs were proposed at the time, one of which being Mozilla's WebActivities which is still in use in B2G (which still exists). The system used in tiles is tentatively named "wishes" so as not to conflict with an existing design, but it's possible that we will end up adopting an existing one. (Capyloon simply uses Web Activities for instance, and that might well be good enough.) My point isn't to gratuitously invent a new approach here, simply to use a temporary agnostic indirection.
And yes, I am shamelessly recycling from a proposal I made almost ten years ago as part of the Web Intents work. Just look at this gorgeous UI design:
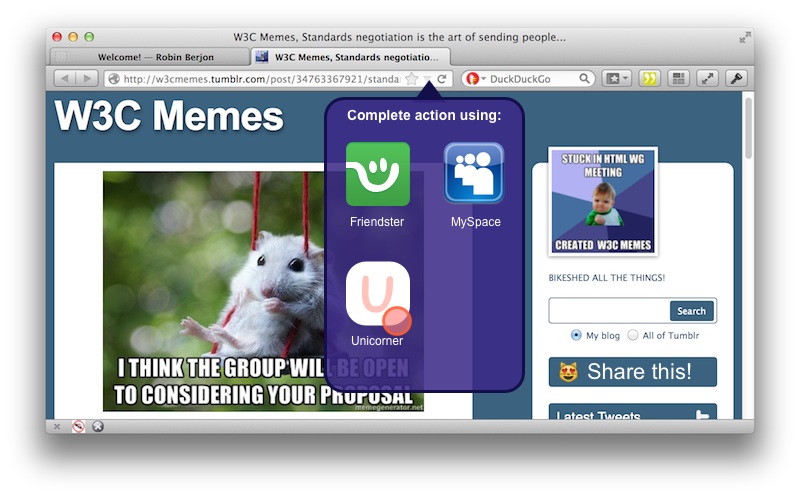
A wish is a verb applied to a type of thing. A tile's metadata describes which wishes it can grant.
wishes: [
// this can pick images and return them
{
"can": "pick",
"what": ["image/*"],
"name": "Select an image from our cat memes collection"
},
// this can create a social post which the user can post
{
"can": "post",
"what": "com.atproto.repo.create",
"name": "Post a cat meme"
}
]
Whereas hyperlinks are nouns — they name things — wishes are verbs. In this sense, they are comparable to HTTP's verbs (methods) but offer richer semantics that sit closer to user applications and that can be fulfilled by the user agent.
When a verb is invoked, the agent typically needs to ask the user what they want to invoked it on or with (e.g. which source pick images from, what to edit with). The tile making a wish has a simple API:
button.onclick = async () => {
const blob = await window.makeWish('pick', { what: ['image/*'] });
if (!blob) return message('Cancelled picking image.');
image.src = URL.createObjectURL(blob);
};
A wish can also be passed data that it can act on. This doesn't require trusting the party that made that wish since that data has to remain on the client.
const res = await fetch(`pic.jpg`); // from inside the tile itself
const blob = await res.blob();
const editedBlob = await window.makeWish('edit', { what: ['image/*'], data: blob });
A tile can handle a wish by listening to the wish event on its window and by interacting with currentWish. (Note that this API design is tricky in that instantiating a wish that isn't already showing with this method and dispatching the event only after it has been registered isn't fun. One alternative is to use a worker, another a promise.)
To make this less abstract, we can walk through a couple of examples. We start with a very basic tile that wants to obtain an image — it doesn't care about the source, that's up to the user:
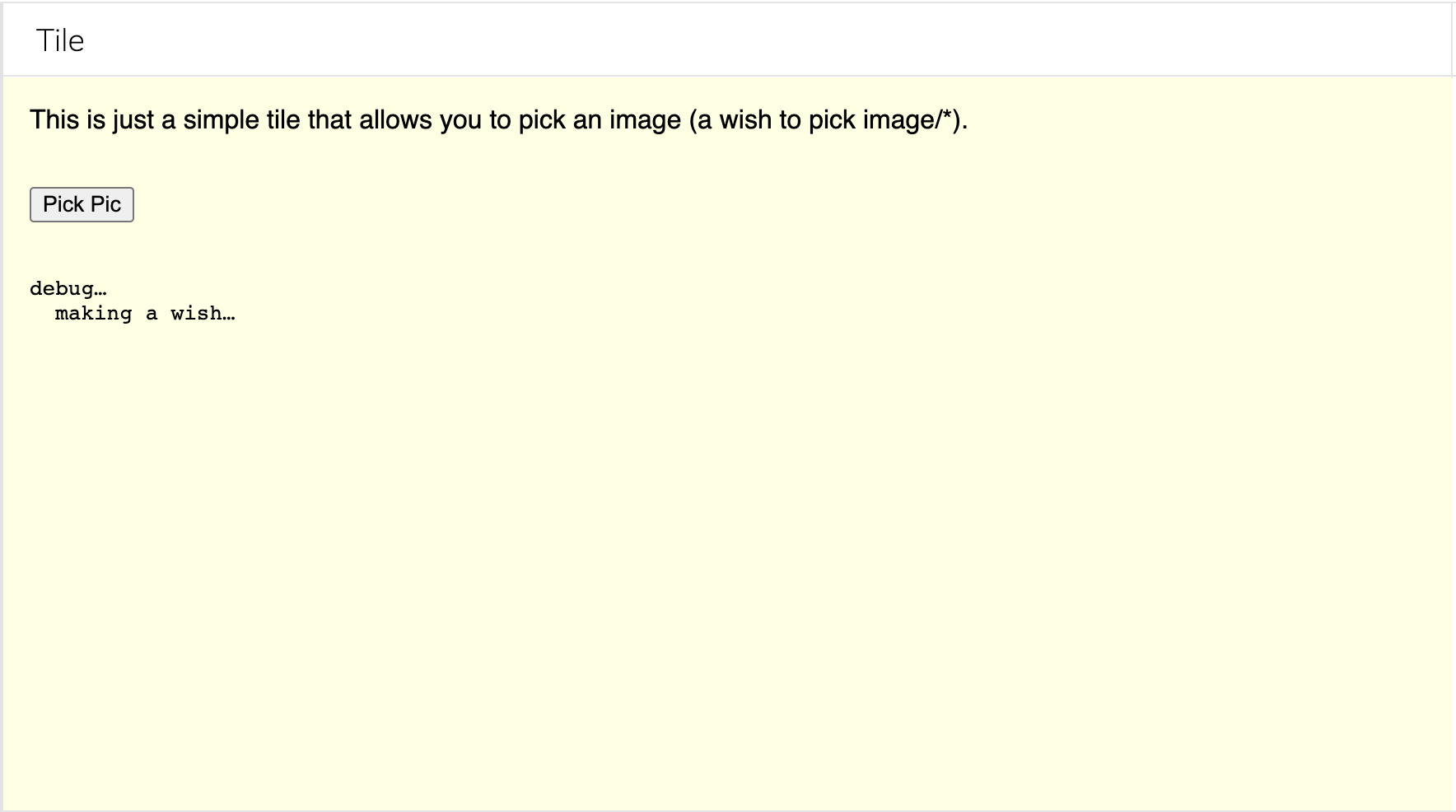
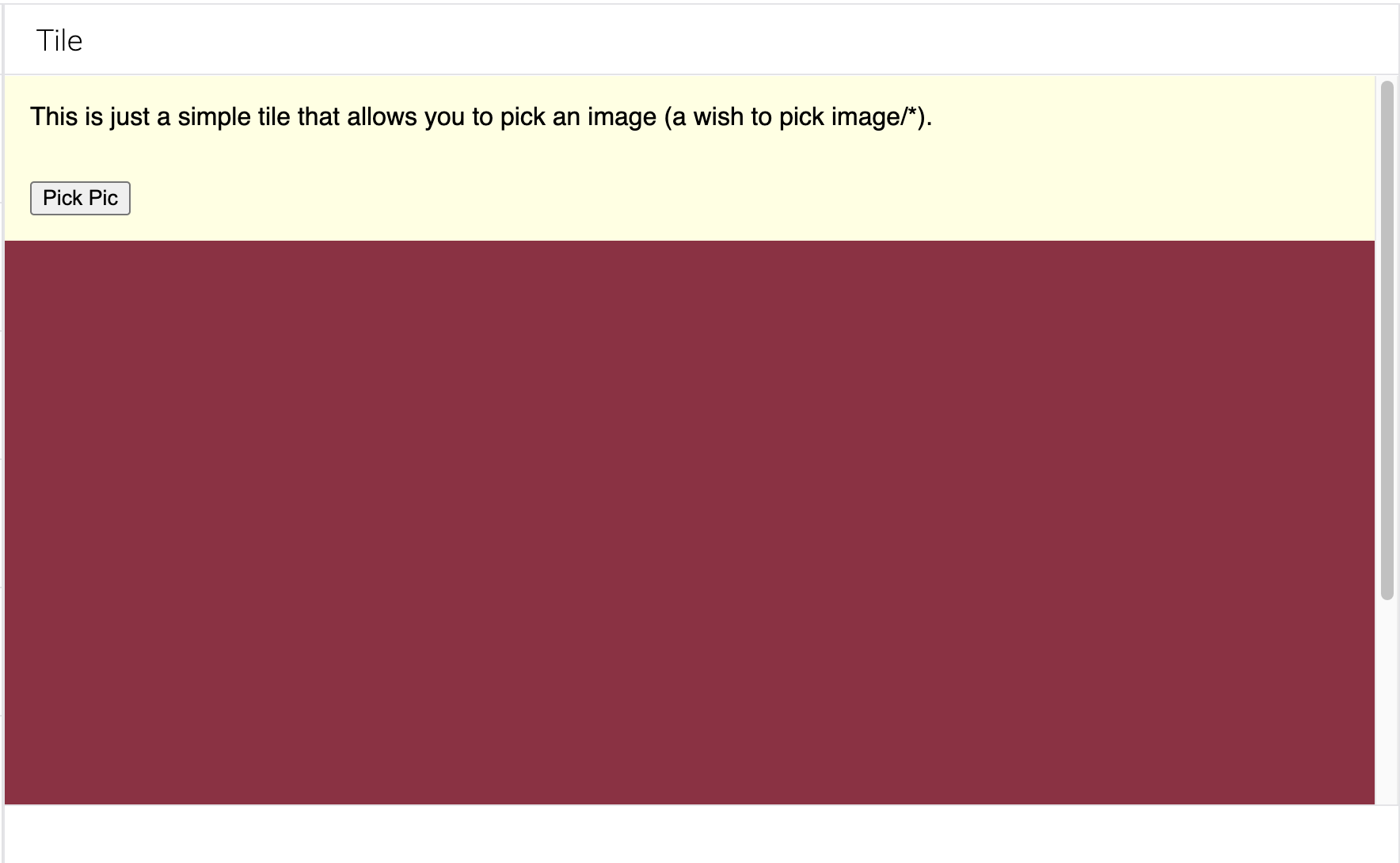
Clicking "Pick Pic" causes that tile to wish to pick and image/*. The user has a set of image sources of their own depending on which tiles they have "installed":
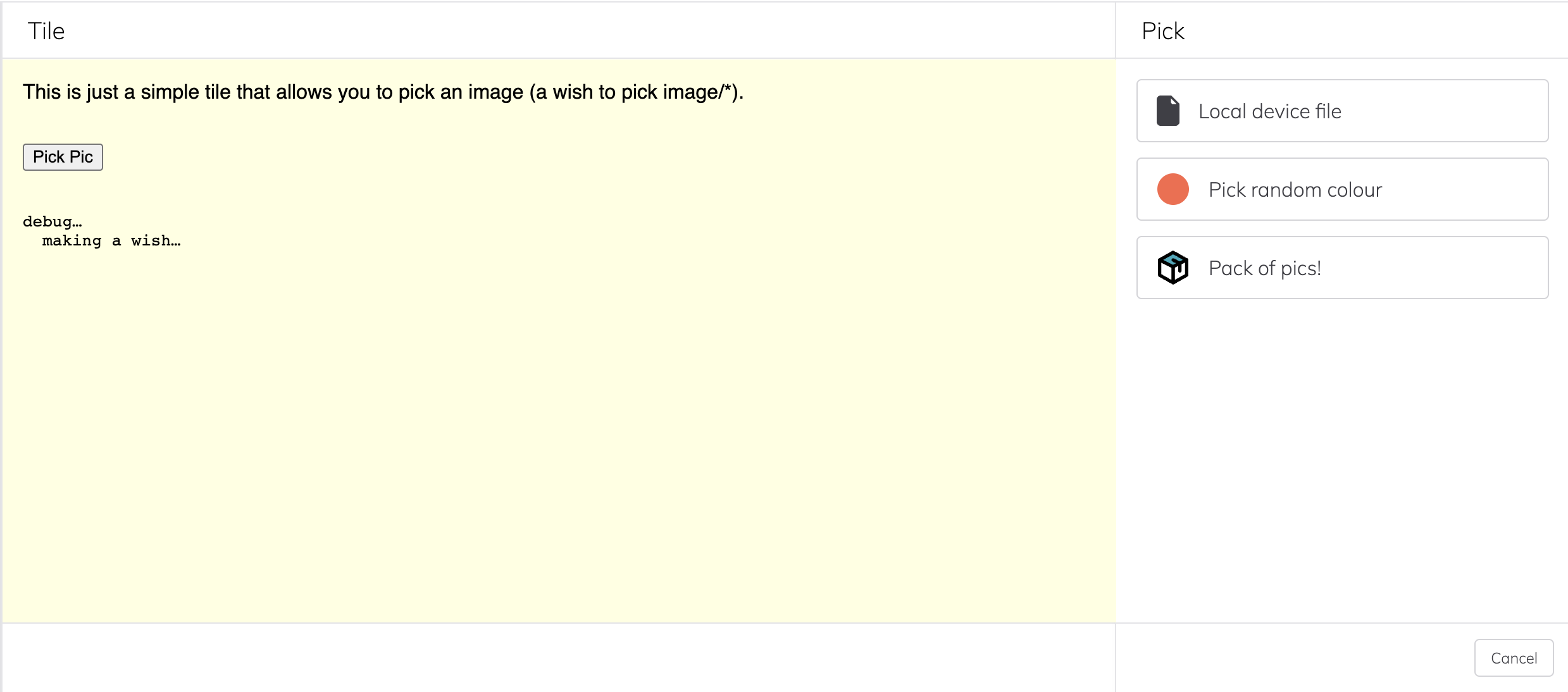
If the user selects "Pick random colour", this loads a tile the sole function of which is to return an image made of a random colour. Not fascinating, perhaps, but we're not here to judge: the Web abides.
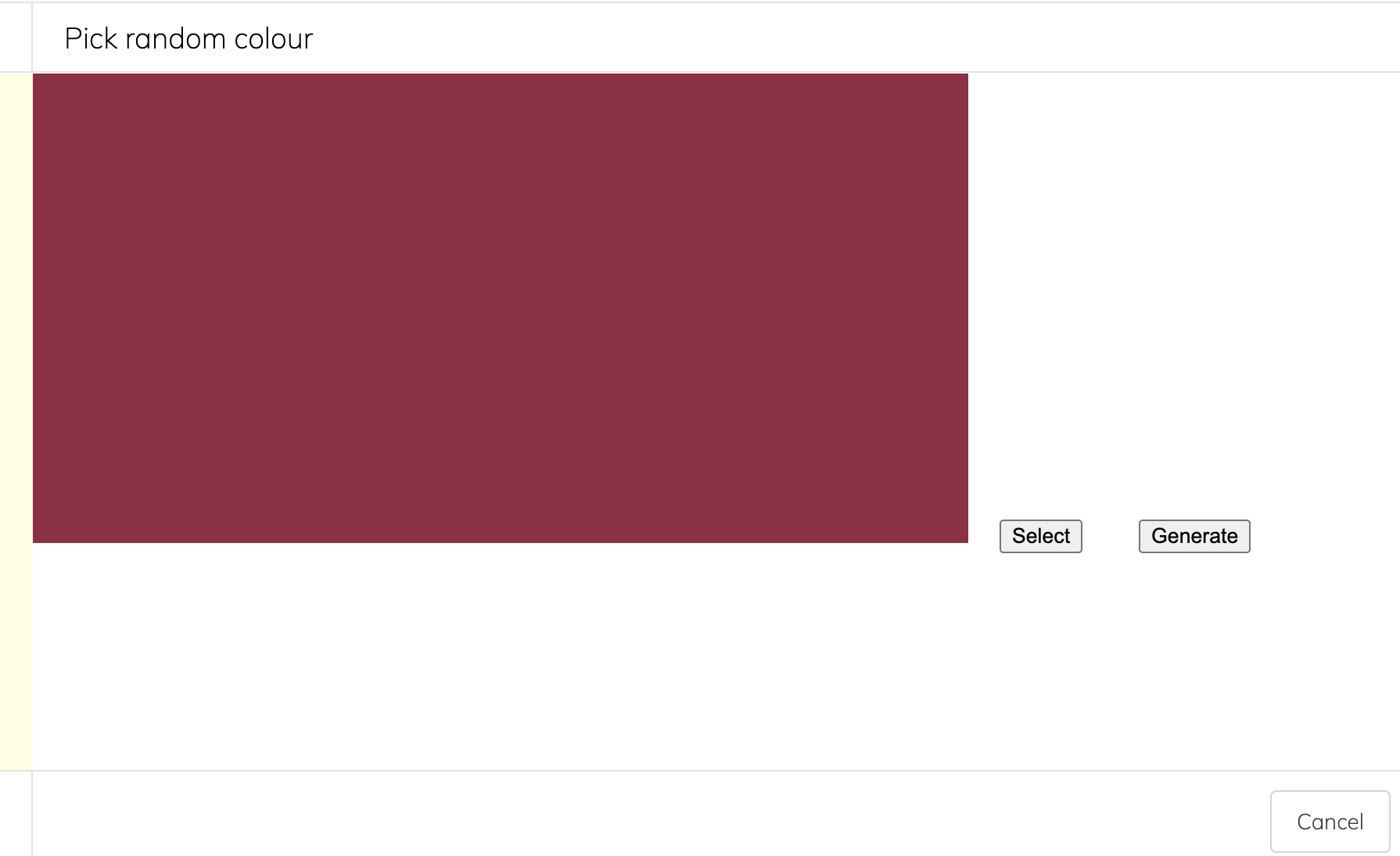
Accepting that lovely shade of burgundy returns an image to the wishing tile:
Wishes can nest arbitrarily — the user ought to just flow from action to action. If instead of going for the random colour we had chosen the "Pack of pics!" (just a tile containing a curated list of pictures), we'd have seen:
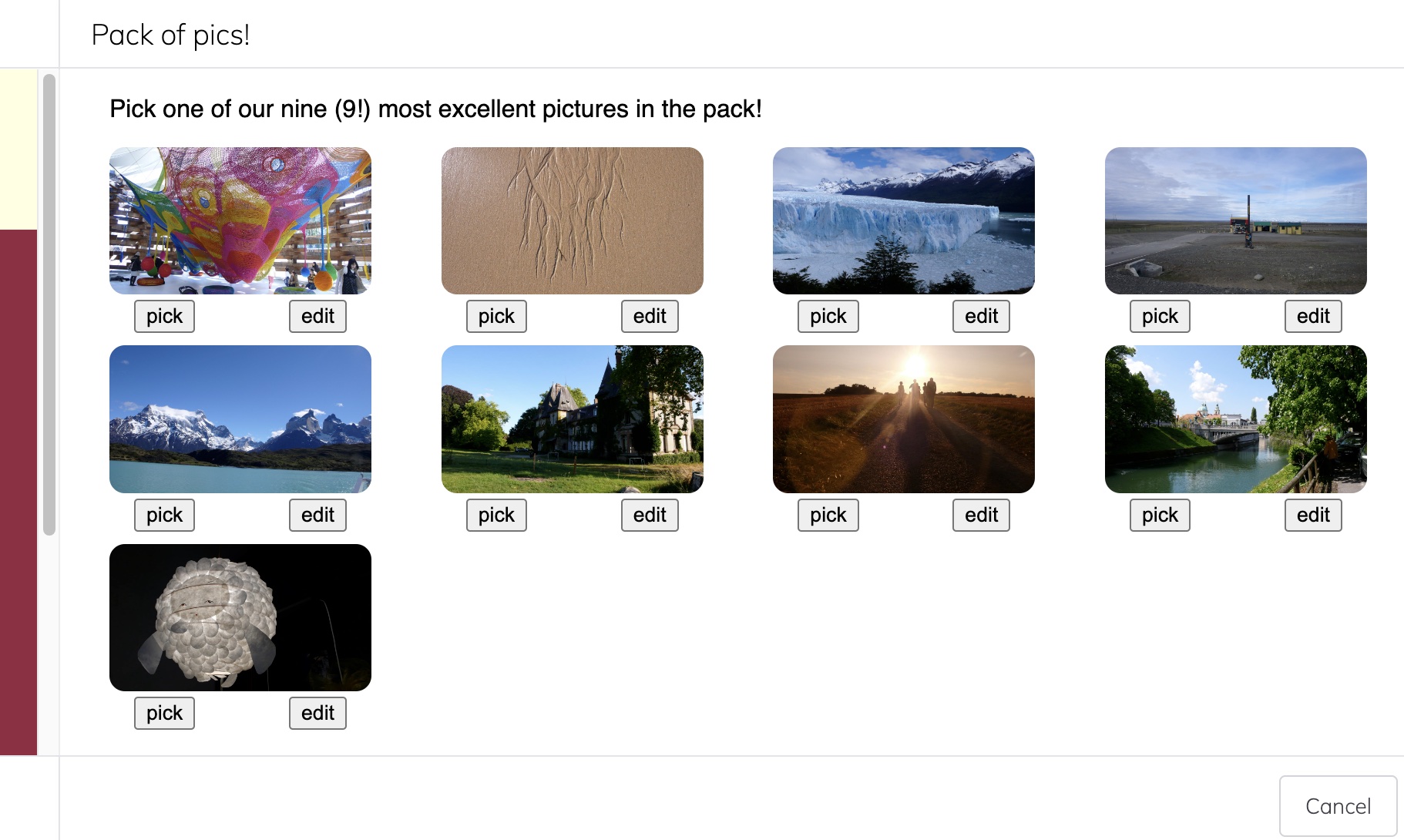
Those images can be picked, in which case they would be returned to the wishing tile, but each can also be edited first. Clicking "edit" with make a wish to edit that image:
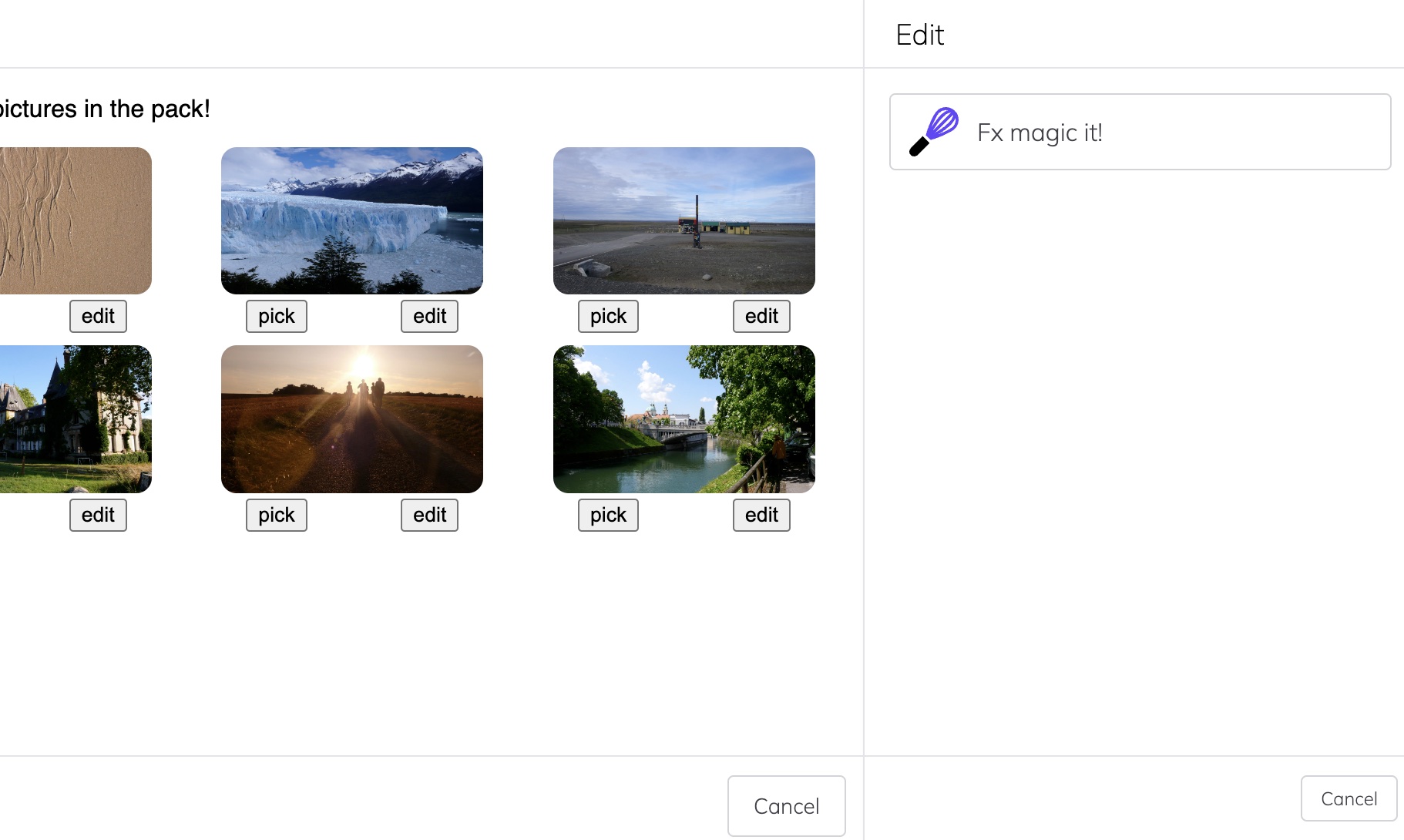
This user only has one image editor (the system also requires a way to discover wishes if you don't have one): Fx Magic. Picking that, we get a highly advanced image manipulation system provided by a completely different party — we use it to invert the blowfish:
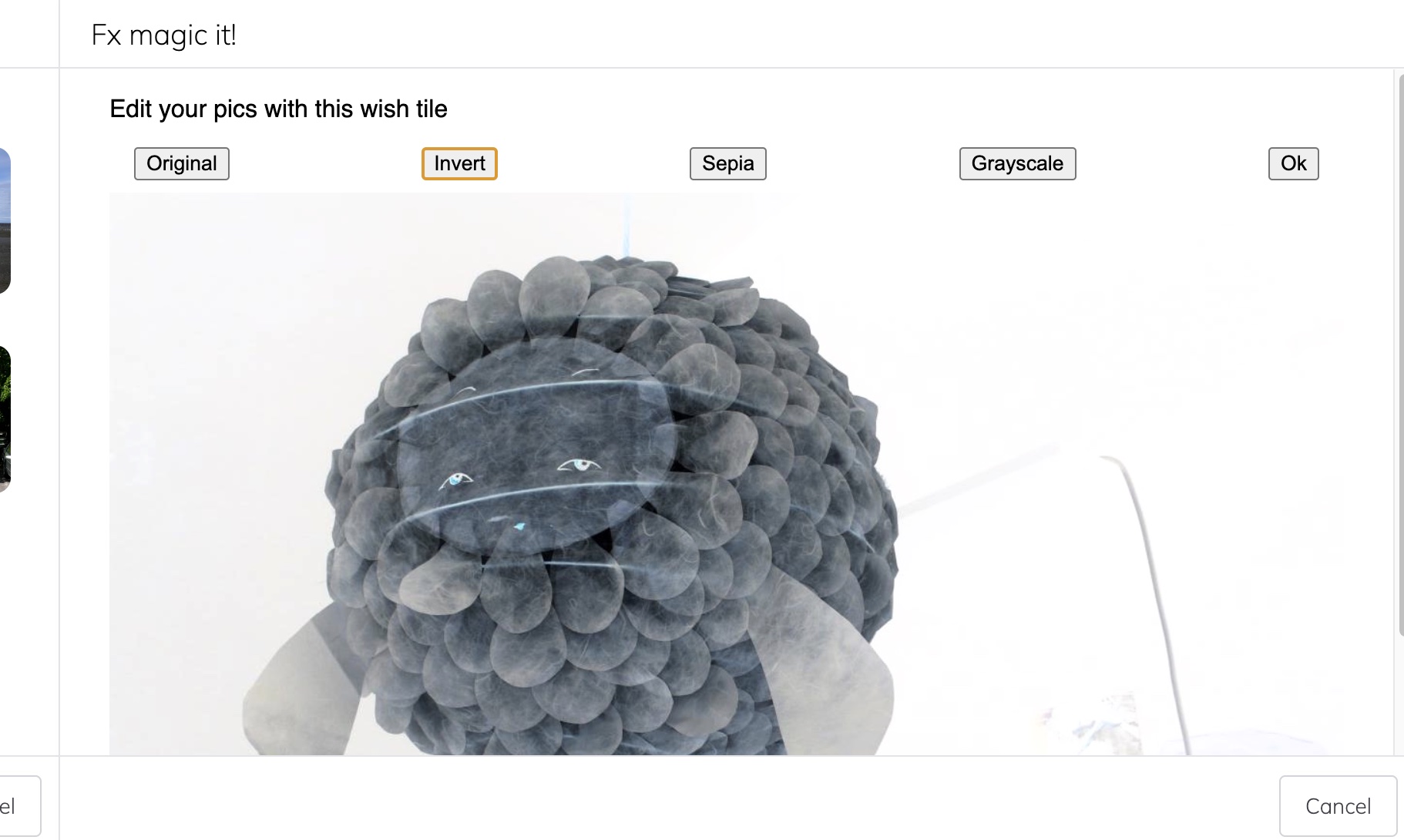
Accepting the edit returns the result to the pack of pic which in turn returns it to the original calling tile:

This is of course a trivial example, but we have made multiple unrelated parties compose and collaborate safely, without any prior knowledge of one another (only the user and agent connect them), in a way that presents no risk to the user of having their data shared with arbitrary parties.
More involved interactions can be required when the wish is not about a simple request/response action. For instance, we can think of a wish the purpose of which is to produce recommendations for the user. The way it works when installed and active is that it receives lists of items of the kind that it knows how to produce recommendations for, it filters out anything that it knows should not be in the list (e.g. I've said I never want to read that author again), it ranks the rest according to whatever applicable criteria (eg. using its own ML model or simply chronologically), and returns that ranking to whatever tile is rendering the list. A wish can be a very thin wrapper around a piece of WASM, for this kind of purpose. Eventually, the difference between a tile and an extension (and between a browser and OS) becomes limited.
Differences from Previous Proposals
Finding primitives and systems to support a more application-oriented (rather than document-oriented) Web has been a persistent problem of the past decades. Some additions have proven useful (e.g. workers) while many others have floundered. Without attempting to compare tiles with all previous approaches (there have been many), it is useful to describe what sets tiles apart. Three things are worth teasing apart here: first, the primitive itself, which is a relatively simple and constrained; second, some consequences in terms of what becomes possible based on that primitive; and third some broader (but brief) philosophical considerations about the overall approach in which this primitive fits and which it furthers.
First, the key primitive underlying tiles is a strong sandboxing model that limits the extraction of data much more severely than prior proposals, once tiles are loaded they cannot communicate back to the network, not even to some origin as with SXG. We don't claim 100% extraction-proof sandboxing because tiles can have links to non-tile web pages and data can be extracted that way. (Those links have to be user-activated, but that only affords so much protection even if nav-tracking protection can help.) It is possible that tiles could be combined with systems that may enable some data to exit under controlled circumstances. However, for a great number of uses the sandboxing is effective. This makes tiles composable in that the security and privacy properties of multiple tiles communicating with one another are the same as those of any given individual tile.
Second, these properties have positive consequences. The sign of a good Web primitive is that it may not do much on its own but when composed with others things start happening. The sandboxing means that we can consider exposing some more powerful capabilities out of the box (notably in the class that creates privacy risk). It also means that we can enable tiles to communicate with one another more. Given that they are composable without additional risk, the properties of a system like Web Intents/Web Activities/Wishes match tiles very well and open the door to strong client-side UI/task composability.
Finally, this primitive has desirable philosophical implications. By moving composition from the server to the client, with loose joints that empower people to easily choose how they wish to compose services, this system significantly increases user agency and shifts power from servers to people. The user agent can also monitor interactions between tiles and intervene when necessary (or at the very least render those interactions available for auditing). Additionally, monolithic bundled apps have been a deeply ingrained user-hostile pattern for a very long time. This approach may finally allow us to move to a new model that aligns with people's expectations better.
One thing that is worth noting is that, because tiles are content addressed, we can get a stronger and more predictable sandboxing as well as a path towards privacy mitigations in content loading since content need not be obtained from its origin. We also get a more permanent Web, and "installing" a tile is as simple as just keeping it around locally — something that is very hard (impossible in the general case) over HTTP. You can just pin your tiles, back them up, etc.
Arguably the biggest lift with tiles is in user interface: they probably do not work in a classic tabbed browser UI and we probably shouldn't try to make that happen. While it is key for the Web to rely on the notion of user agents, there is nothing to say that the current UI paradigm is right.
I will keep referring to tiles as I move through thoughts about PDSs, apps on the web, or fixing social media.
This post is part of a series on reimagining parts of the Web. You can read the other entries in the series at:
- Building the Next Web
- The Web Is For User Agency
- You're Gonna Need A Bigger Browser
- Web Tiles
- ActivityPub Over ATProto
Acknowledgements
Many thanks to the following excellent people (in alphabetical order) for their invaluable feedback: Amy Guy, Benjamin Goering, Ben Harnett, Blaine Cook, Boris Mann, Brian Kardell, Brooklyn Zelenka, Dave Justice, Dietrich Ayala, Dominique Hazaël-Massieux, Fabrice Desré, Ian Preston, Juan Caballero, Kjetil Kjernsmo, Marcin Rataj, Margaux Vitre, Maria Farrell, and Tess O'Connor. Needless to say, anything dumb and stupid in this article is entirely mine.